Well, time for another adventure, and with every adventure it begins with a very silly thought that isn’t even mine this time:
 “I wonder if one can fit the entire bible on a TI-Nspire CX with mViewer GX PDF converter”, says our friend DJ
“I wonder if one can fit the entire bible on a TI-Nspire CX with mViewer GX PDF converter”, says our friend DJ
And there you go, am I searching for the answer:
That’s the Wikipedia effect right there, you look for something and before you know you know everything there is to know about religion and now you’re on some completely unrelated page about quantum theory.me: trying to find out how big the Bible is in terms of computer storage because someone asked on Discord
— Yuki 雪🏳️⚧️ (@juju2143) January 9, 2020
me, literally 30 seconds later: https://t.co/qQiEqTKnCk
So I downloaded the whole King James Version on Project Gutenberg, removed the header and footer they put there for better text processing, it’s about 4.4 MB, converted to PDF, since the format support plain text directly it’s not that much more (I got a 3 MB file), then converted to work on a TI-Nspire with the mViewer GX PDF converter I… I think I broke TI-Planet. Well, from what it was able to generate (76 pages out of 1664, pretty much the book of Genesis?) each 10 pages is about 1.3 MB, so by extension the whole thing should be around 216 MB. We’re dealing with images now, and not just plain text, so yeah. Could be lower if you set the resolution to something almost unreadable, but at this point you’re better using a plain text reader on your calc.
So in conclusion, maybe. Maybe you can manage to do it. But it’s gonna take most of your calc space, which is, with nothing installed, is about 100 MB.
But wait a minute, we have another contender…
what are you talkin’ about MintyDidn't they manage to cram the whole Bible on a GameBoy cartridge?
— Minty Root (@Minty_Root) January 9, 2020
Oh God, we’re gonna have some fun with that. Sure enough, there was an unlicensed King James Bible for the Game Boy published by Wisdom Tree in 1994, if you want to see it in action there was an Angry Video Game Nerd episode about it, but what’s amazing about it is that is that the ROM is only one megabyte, including the entire text of the Bible, a search engine and two word search games.
(Note, if you’re emulating it, use BGB. Any other emulator will introduce bugs due to its weird mapping no one will understand except BGB. Of course, I will not provide the ROM for the usual copyright reasons.)
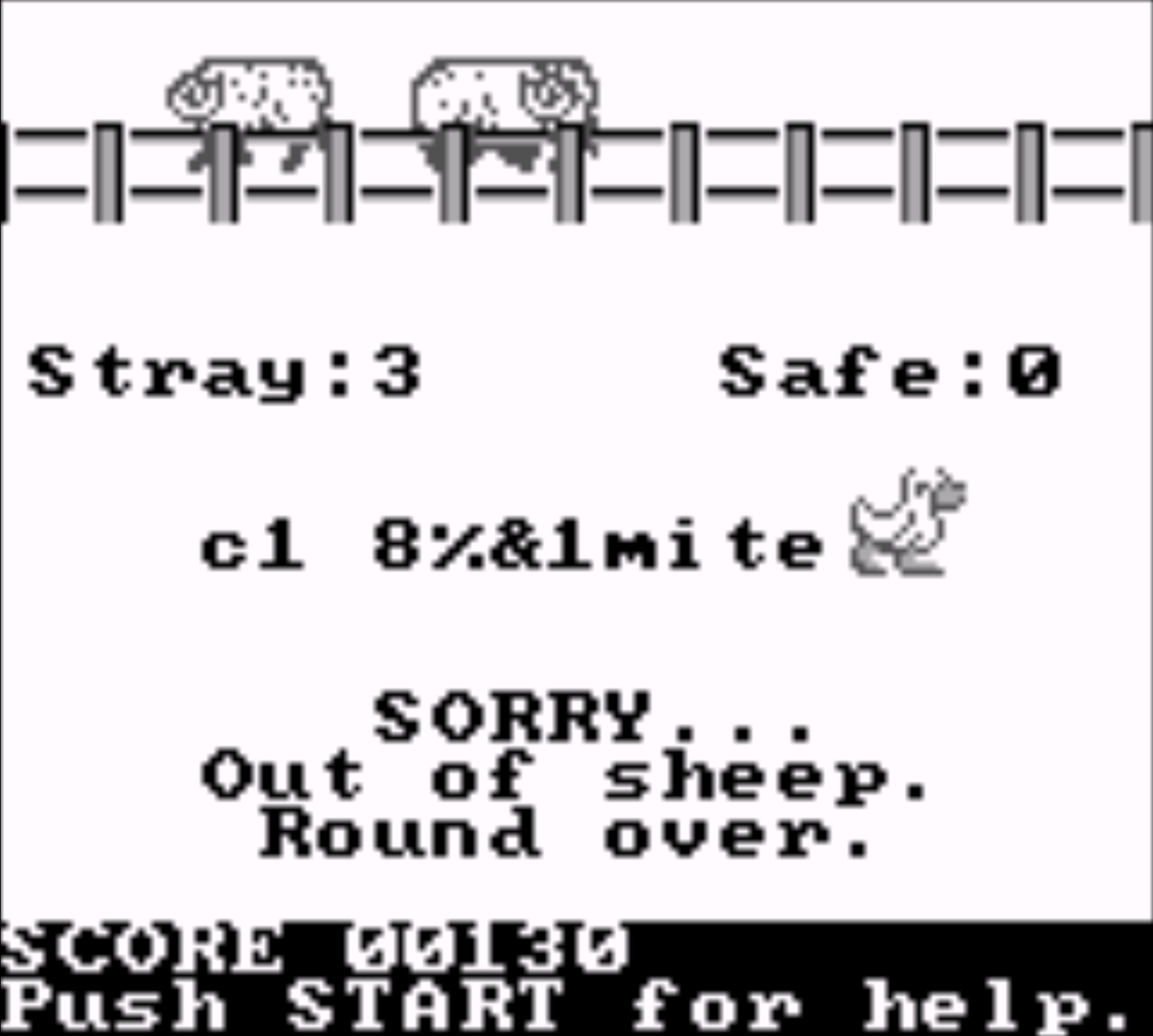 Here’s what I mean. The reader will crash and the games will make you guess garbage you can’t input.
Here’s what I mean. The reader will crash and the games will make you guess garbage you can’t input.
So for fun, with the KJB text I have in hand, I tested some of the most common compression utilities, all set to their maximum/best/slowest settings:
| Compression | Size | Ratio |
|---|---|---|
| zpaq -m5 | 739407 | 16.682% |
| bzip2 -9 | 993406 | 22.412% |
| lzma -9 | 1048408 | 23.653% |
| xz -9 | 1048616 | 23.658% |
| 7z -mx9 | 1048710 | 23.660% |
| zstd –ultra -22 | 1068137 | 24.099% |
| rar -m5 | 1142360 | 25.773% |
| gzip -9 | 1385457 | 31.258% |
| zip -9 | 1385595 | 31.261% |
| lz4 -9 | 1596418 | 36.017% |
| lzop -9 | 1611939 | 36.367% |
| Uncompressed | 4432375 | 100% |
Note that some of these are different containers for the same algorithm, hence similar filesizes, and some of them are better suited for other uses, e.g. lz4 and lzop are better to decompress the Linux kernel at boot time because they’re fast and use less memory, and zstd is starting to replace xz because it’s 1300% faster despite producing slightly bigger files.
So, with our goal of a ROM size of 1048576 bytes with enough space left to fit some code for the decompressor that is fast enough to be playable on a Game Boy, a good-looking UI, a search engine and some games, only zpaq and bzip2 would fit the bill, and even then. (Special mention to lzma which fits a megabyte almost exactly.) Most of those algorithms were devised after 1994, bzip2 in particular was devised between 1996 and 2000, but even though it has the best compression ratio it’s way slower than gzip.
Anyway, I’m not an expert, but yeah, there’s more efficient compressors out there, but we don’t usually use them because they’re either experimental and/or very, very slow, the PAQ ones in particular. So I’d imagine a slow compressor with a fast decompressor that is tuned for English text.
So, now that we have our compression benchmark on file size, it’s appropriate to make a decompression benchmark based on time, because that’s what we need, right? So here’s some tests under a normal load on my good ol’ iMac 27" mid-2011 running Linux (don’t laugh, it’s old af but it’s still my daily driver and it still works for me) using the above files decompressed to /dev/null and ran several times until it gives somewhat consistent approximate results. I didn’t bothered to time the software during the compression phase because it’s irrelevant to our use case (and I haven’t thought of that when I tested), but all of them were quite fast except zpaq.
| Decompression | Time (s) |
|---|---|
| lz4 | 0.008 |
| zstd | 0.015 |
| lzo | 0.016 |
| rar | 0.035 |
| gzip/zip | 0.040 |
| lzma/xz/7z | 0.080 |
| bzip | 20.210 |
| zpaq | 16.203 |
So you have a list that is rather backwards from the other list, with the notable exception of zpaq. Of course, it’s going to be at least a thousand times slower on a Game Boy (could try to run these tests on a 486 or something to get better numbers), and it’s kinda hard to quantify compessed bytes versus decompression time, but it’s quite enough to draw conclusions about what kind of compression we’re dealing with. The more compressed it is, the slower it will be, which is rather in contradiction with our “efficient compressor, fast decompressor” theory. One solution would be decompressing in chunks only when needed, and the Game Boy screen is rather small, so it could work. The search engine have the ability to search words fast and the games included deals with words too, so maybe there is something to do with whole words as well, such as mapping words to IDs or a similar technique.
Now time to actually figure out what the decompression is in that bible ROM. Sadly, I’m not well-versed in Z80 debugging to figure it out, but I can already imagine it’s a very efficient algorithm even by today’s standards and if you figure it out it could probably compete with gzip and zstd or something.
I have ideas of grandeur here, as usualPlot twist: you reverse engineer some unlicensed bible reader for the Game Boy from 1994 and you find a previously unknown compression algorithm that can compete with today's algorithms
— Yuki 雪🏳️⚧️ (@juju2143) January 10, 2020
Wanted: someone with enough Z80 debugging knowledge to figure it out and get the credit
So there you go, open-ended thoughts about obscure ways to read the Bible. If you have any information about it or you feel like doing the gruesome work of debugging the ROM, feel free to comment below or share it with me on Twitter, and I will make a follow-up eventually, a part 2 if you will, likewise if you have any suggestions such as adding a compression algorithm I can review for the tables above.
It’s a pretty interesting project since, well, I’m not that religious and I’m definitely not the kind of idiot who quote the Bible out of context (please don’t do that) but I still like to research about it, and I still consider myself as a nice Christian who believe in science. I always said that it’s about what you personally believe and not what others believe, always read everything with a rational mind and uh, yeah I could rant a long time about that and it’s not that much the point here, maybe for another time, but yeah. If you followed up until here and you want to look out for more about this, well for that quite interesting ROM that is, I wish you good luck, and I’ll see you for another blog post :)